
We’ve been playing with the Pico over here. Some of us have been going more in-depth than others. And since everyone starts with a different set of experiences, a historical perspective, you might say, we all sort of hit it from another angle.
A common angle to come at this unique and delicious combination is from a general familiarity with Python. That’s where I came from. I had written Python scripts to do various things. I had taken it to the next level and written tkinter visual apps for the Raspberry Pi 3 and for desktop OSes.
But I quickly got the understanding that MicroPython is not full Python. Is it safe to say it’s a highly-specific subset of Python?
So obviously my first question is, “what can I DO with it?”
So, you could go out and find things that have been done, and adapt them, and we’ve all done that.
Or…
You could ask your Pico directly.
Go install Thonny, if you haven’t already, and get it talking to your Pico. I’ll wait. And I won’t walk you through that. That’s beyond the scope of this little post.
[jeopardy theme song plays while I wait patiently…]
OK. You back? Let’s do this.
So hopefully you’ve connected up your Pico and been prompted to flash the MicroPython firmware to it. That’s all kind of automatic, right?
Now, create a new file in Thonny. Let’s call it fafo.py (fuck around, find out).
Put the following very simple script in it.
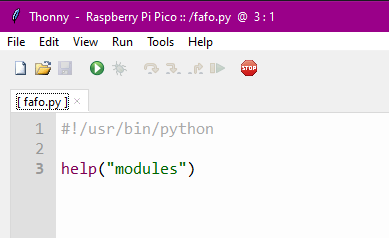
Save it (you should be prompted to choose whether you’re saving it to your PC or to your Pico — choose the Pico).
Now run it. You should have a shell in the bottom half of your Thonny window and should see the following output:
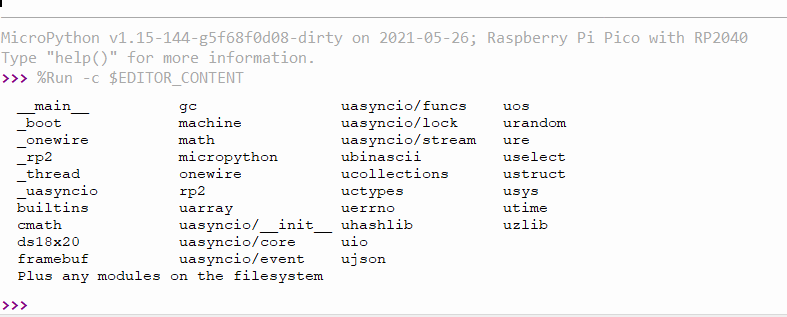
Congratulations. You’ve just asked your Pico politely for a list of modules, and it has responded with a list of all built-in modules (modules that are built in to the MicroPython firmware you flashed onto your Pico). Note the last line: “Plus any modules on the filesystem.” It’s not aware of any custom modules you may have written, borrowed, used within its governing license, or stolen, and dropped into the MicroPython filesystem.
Let’s take this a step further. What if you wanted to know what functions and classes are available within a module? Let’s try this:
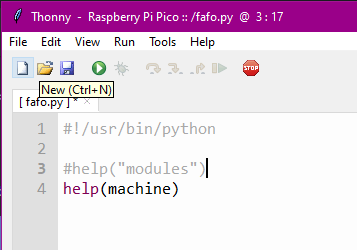
Now you’ve asked your friendly little Pico to give you help on the module named “machine.” Note that you do not quote the module you are requesting help with. If you do, it thinks you’re asking help with strings, because “machine” is a string. Yeah, I don’t know why “modules” is quoted and machine is not. Let’s keep going anyway. Hit run. (In my setups on Mac and Win, you don’t need to save anymore once you’ve saved to Pico, it will automatically save before running, so unless you’re saving a new file, you can just hit run.

That’s pretty cool. And now you know you can ask it for help on any module. But what if you want to know more about a class within a module? Let’s take a look:
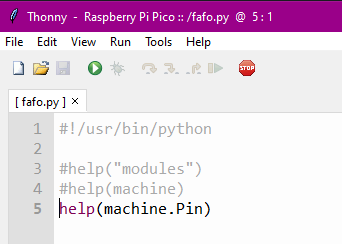
Hello, my little Pico friend, would you be kind enough to tell me more about the Pin class within the machine module?
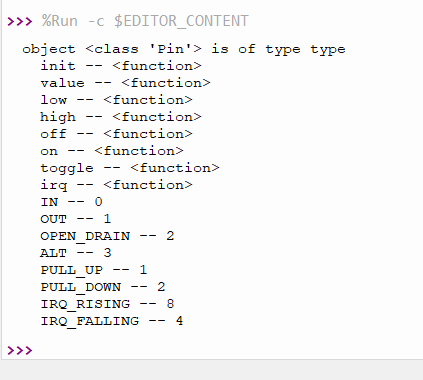
Now you have a super helpful list of functions (methods) and constants associated with the Pin.class of the machine module. Now go forth and play with all the other modules. Find something that takes you to your happy place. I did:
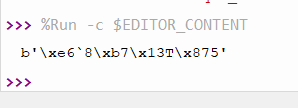
This is actually what I came here looking for, a unique ID function.
So I plugged in another Pico, flashed the MP firmware on it, then hit run again. As predicted, it automatically saved it to the Pico, not even realizing I had swapped Picos, then ran it.
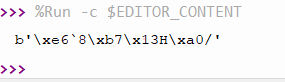
Mission accomplished!